Matplotlib 그래프 2 1편은 아래에서 확인하실 수 있습니다:) https://wonhwa1.blogspot.com/2022/11/python-matplotlib.html 데이터 준비 1편에서 사용한 csv데이터를 준비해 주세요. 또는 아래의 링크에서 다운받으실 수 있습니다. https://www.kaggle.com/imakash3011/customer-personality-analysis 다변량 그래프 그리기 다변량 그래프는 변수가 여러 개 있는 그래프입니다. 이번 포스팅에는 변수를 4개를 추가하여 그래프를 그리는 방법을 알아보도록 하겠습니다. x축: MntMeatProducts(육류구매량) y축: MntWines(와인구매량) 색구분: Edu_level(학력) 사이즈구분: NumWebPurchases(웹사이트구매횟수) 이렇게 4개의 변수를 그래프로 표현해 보겠습니다. 기존 csv를 불러온 df에서 null 값이 있으면 0으로 일괄대체를 해준 후 나머지 과정을 진행합니다. 먼저 학력별로 색 구분을 하려면 str데이터인 학력을 문자에서 숫자로 변환하는 작업이 필요합니다. 이 작업을 아래의 함수를 써서 학력을 숫자로 바꾼 후, 바꾼 숫자들을 'Edu_level'이라는 학력 컬럼을 새로 만들어 입력 하겠습니다. import pandas as pd import matplotlib.pyplot as plt from matplotlib import font_manager,rc # 한글 폰트 설정 font_location = 'C:/Windows/Fonts/MALGUNSL.TTF' #맑은고딕 font_name = font_manager.FontProperties(fname=font_location).get_name() rc('font',family=font_name) #데이터 셋 불러오기 df = pd.read_csv('marketing_campaign.csv',sep='\t') # nul...
Apply
종종 pandas로 csv 파일을 열어 dataframe을 만들 때,
각 행을 계산한다던가, 열을 계산하여야 할 때가 있습니다.
이때 pandas 의 apply 메서드를 사용하면 만들어 둔 함수를 간편하게 적용하여 계산이 가능합니다.
데이터 준비
데이터는 kaggle의 Lemonade-Orange-stand를 사용해 보겠습니다.
이 데이터는 각 날짜의 레몬, 오렌지 에이드 판매량을 보여주는 데이터셋입니다.
링크를 들어가서 Lemonade2016-2.csv 파일을 다운받아 줍니다.
그 후 csv파일을 아래와 같이 열어 줍니다.
import pandas as pd
df = pd.read_csv('Lemonade2016-2.csv')
df 
- Date: 날짜
- Location: 판매장소(공원/해변가)
- Lemon: 레몬에이드 판매량(잔)
- Orange: 오렌지에이드 판매량(잔)
- Temperature: 기온(화씨/ºF)
- Leaflets: 배포한 전단지 수
- Price: 가격($)
Series에서 apply 적용하기
1개의 인자를 전달받는 함수
현재 df에 있는 temperature은 화씨온도로 한국에서 쓰는 섭씨온도랑 단위가 다릅니다.
때문에 온도를 이해하기 쉽게 섭씨 온도로 바꿔주는 작업을 해보도록 하겠습니다.
화씨온도에서 섭씨온도로 변환하는 식은 아래와 같습니다.
ºF(화씨) -> ºC(섭씨)
°C = (°F−32)×5/9
이것을 'to_C'라는 함수로 만들어 보겠습니다.
#화씨->섭씨 함수
# (temperature - 32) * 5 / 9
def to_C(x):
C = (x - 32) * 5 / 9
# 소수 셋째자리에서 반올림
C = round(C,2)
return C 그리고 df에서 따로 날짜컬럼만 빼어서 apply 함수 적용 후 새로운 df열에 할당해 주도록 하겠습니다.
# 기온(temperature)을 섭씨(ºC)로 변환
temp = df['Temperature']
# apply 함수 적용 후 새로운 열에 섭씨온도 추가해 주기
df['temp_C'] = temp.apply(to_C)
df 
오른쪽 맨 끝열에 섭씨 온도가 잘 추가되었습니다.
2개의 인자를 전달받는 함수
25센트짜리 레몬에이드 판매액을 구해보자
이번에는 각 날짜의 레몬에이드 판매액이 얼마인지 apply를 사용해 구해보도록 하겠습니다.
레몬에이드 판매액은
레몬에이드 판매 수 x 가격
으로 구할 수 있습니다.
이번에는 레몬에이드가 25센트일때의 그날의 판매액을 구하는 것이므로
먼저 레몬에이드가 25센트인 날만 필터링하여줍니다.
# price가 0.25인것만 필터링
cent_25 = df[df['Price'] == 0.25]
cent_25 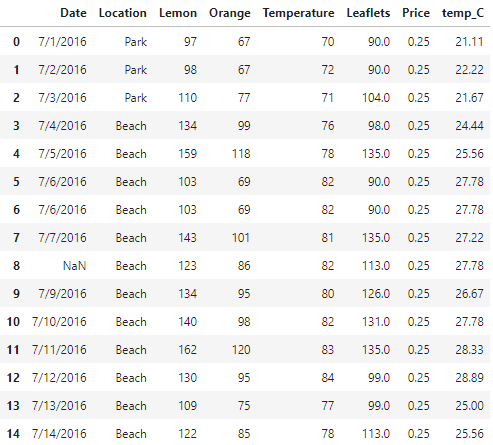
이렇게 25센트인 날만 추출이 완료되었습니다.
그 후, 판매액을 구하는 함수를 만들어 apply로 적용해 줍니다.
apply 적용 시 Lemon열에서 적용하여 줍니다. price는 0.25로 모든 열이 같으므로
price 인자를 전달할 때 price=0.25로 고정하여 줍니다.
#판매액 을 구하는 함수
def lemon_money(x, price):
total = x * price
return total
cent_25['Lemon'].apply(lemon_money,price=0.25) 
이렇게 판매액 계산이 완료되었습니다.
Dataframe에서 apply 적용하기
3개의 인자를 입력받아 계산하는 경우
이번에는 레몬 에이드와 오렌지 에이드 판매량을 합쳐 각 날짜의 총 판매액을 구해보도록 하겠습니다.
이것을 함수로 작성한다면 일반적인 경우는 아래와 같이 작성할 것 입니다.
(레몬에이드 판매량 +오렌지에이드 판매량) *가격
# 보통 생각하는 함수
# (레몬에이드 + 오렌지에이드)* 가격 함수
def total(x,y,price):
total_money = (x+y)*price
return total_money 하지만 dataframe에 apply를 적용할 때는 행 단위 또는 열 단위로만 값을 입력받기 때문에,
위의 함수식을 한개의 인자를 받는 함수로 바꾸어야 합니다.
그 후 이 함수식 안에서 3개의 인자를 생성하는 방향으로 함수를 수정하겠습니다.
이 때, df에서 사용하는 값이 각 행의 'Lemon', 'Orange', 'Price' 컬럼 이므로
이를 각각 함수 내에서 x,y,price라는 변수 생성후 열 번호로 할당을 해주도록 하겠습니다.
각 컬럼의 위치와 인덱스를 아래와 같이 확인하여 줍니다.
#컬럼확인
df.columns 
#컬럼 번호 확인
for itr,i in enumerate(df.columns):
print(itr,' : ',i) 
그 후 함수를 한 개의 인자값을 받는 함수로 수정하여 줍니다.
# 1개의 인자값을 가지는 함수로 변경
# x=레몬에이드,y=오렌지에이드,price=가격 각각 열 위치로 변수 할당
def total(col):
x = col[2] #Lemon
y = col[3] #Orange
price = col[6] #Price
total_money = (x+y)*price
return total_money 마지막으로, apply를 사용하여 해당 함수를 적용하여 줍니다.
각 열을 인자값으로 사용하므로 axis=1로 설정해 줍니다.(axis=0은 행방향)
#df에 적용하여 리턴값 새 열에 할당
# 열 기준이므로 axis = 1
df['total'] = df.apply(total,axis=1)
df 
이렇게 total 열에 총 판매액 계산이 잘 되었습니다.
전체코드
import pandas as pd
df = pd.read_csv('Lemonade2016-2.csv')
# 기온(temperature)을 섭씨(ºC)로 변환
temp = df['Temperature']
#화씨->섭씨 함수
# (temperature - 32) * 5 / 9
def to_C(x):
C = (x - 32) * 5 / 9
# 소수 셋째자리에서 반올림
C = round(C,2)
return C
# apply 함수 적용 후 새로운 열에 섭씨온도 추가해 주기
df['temp_C'] = temp.apply(to_C)
# price가 0.25인것만 필터링
cent_25 = df[df['Price'] == 0.25]
#판매액 을 구하는 함수
def lemon_money(x, price):
total = x * price
return total
cent_25['Lemon'].apply(lemon_money,price=0.25)
#컬럼확인
df.columns
#컬럼 번호 확인
for itr,i in enumerate(df.columns):
print(itr,' : ',i)
# 1개의 인자값을 가지는 함수로 변경
# x=레몬에이드,y=오렌지에이드,price=가격 각각 열 위치로 변수 할당
def total(col):
x = col[2] #Lemon
y = col[3] #Orange
price = col[6] #Price
total_money = (x+y)*price
return total_money
#df에 적용하여 리턴값 새 열에 할당
# 열 기준이므로 axis = 1
df['total'] = df.apply(total,axis=1)
df 참고자료
도서) Do it! 데이터 분석을 위한 판다스 입문
마무리
pandas apply 메서드는 활용도가 높으므로 앞으로 유용하게 사용하셨으면 좋겠습니다.
댓글
댓글 쓰기